NLP: Deep learning for relation extraction

Oskar Handmark
Founder & Venture lead

Originally published in 2016. Hence, this post is outdated. Modern Neural network designs and transformer models have taken over. Yet, it's relevance is still high as it outlines some of the main concepts for modern NLP.
In this post, we will be focusing on text mining and review analysis. We’ll roll our own deep learning implementation for relation extraction. Imagine you have a large pool of reviews about your company or your products and you want a quick overview of what descriptors or adjectives are mentioned about certain parts or features of your company or products. The end goal looks something like this:
 Aggregated result for hypothetical headphone reviews.
Aggregated result for hypothetical headphone reviews.Performing this over thousands of reviews and aggregating this together builds a pretty powerful summarization tool that can be used to get a quick and thorough picture of what is said about a specific company or product. Moreover, we can zoom in on areas that we are specifically interested in, such as delivery times or the service quality. Since there exists so many good tools for sentiment analysis already, our focus will be on implementing relation extraction. Here are some examples of what we would like to extract, given the review sentence.
"X has the cheapest prices and super quick delivery"
prices - cheapest delivery - super quick
"I was impressed by the battery life"
battery life - impressive
We will use a few NLP techniques related to information extraction to solve this problem. Roughly, we’ll give a few examples of how we want it to work along with data relevant to each word in our sentences, and let a neural network figure out what patterns may be hidden in there. I want to emphasize the fact that we will not include the actual word itself as a feature, which otherwise is a pretty common approach. This means that the model will generalize better to words it has not seen in its training set.
Outlined below are the steps we'll take to implement this.
1. Annotation: We will annotate a training set which holds examples of a few sentences and what relations we would like to extract from each.
2. Feature selection: Given each word and its context in a sentence, find relevant features and as much information as possible surrounding that word. Attribute a feature vector to each word.
3. Model training: Given feature vectors and correct prediction labels for each word in our training set, train a neural network to categorize words into five different categories.
4. Linking: Given our model’s prediction for a sentence, the case might be that there are multiple entities and descriptors in the sentence. This manual step allows descriptors and entities to form the correct bonds.
1. Annotation
The power of machine learning is when you’re not sure how to algorithmically solve a problem, as long as you provide some examples of how you want it to work, and what’s relevant in your data, you can get a pretty close estimate.
We’ll create some examples for our model. We’ll use a chunking strategy to denote groups of entities or descriptors. For example, if the battery life was fantastically super amazing, we’d want to make sure all of those words make it in there as a group. We’ll use a version of the BIO (Begin, Inside, Outside) labeling standard to mark when word groups starts and when they end:
Word | Label |
|---|---|
The | - |
battery | b.ENT |
life | i.ENT |
is | - |
fantastically | b.DESC |
super | i.DESC |
amazing | i.DESC |
. | - |
We’d want to include as many examples as possible, and after writing a couple yourself, you realize that this is probably not what you were set out to do in life. Consider outsourcing this to Mech Turk.
This step is manual, but do not be fooled by it’s trivial appearance. It is very important that labelling is done meticulously with persistent methodology. If you do not follow the same approach throughout your entire training set, you will confuse your model during training.
2. Feature selection
Now that we have some labelled data, all we need is features for our model. A feature is a single measurable property about one of your training examples. For each of your training examples there are multiple features. In our case, a feature is information about each word, how they relate to other words, and what properties they have. There’s quite a few libraries and services for extracting features from text, such as SpaCy, TextRazor and NLTK. We’ll use Stanford CoreNLP because it has one of the best dependency parsers in the world.
Dependency parse trees
We can use dependency parse trees to extract the syntactic structure of our sentences. This will be helpful since it gives us information about the part-of-speech (POS) tags of the words. A POS-tag is a word category which describes the grammatical properties of the word, a few examples would be noun, verb and adjective. The dependency parse tree also gives us information about how the words structurally relate to other words. This is represented as in-and out links to and from the words in the sentence. Stanford CoreNLP uses the Universal Dependencies standard to represent the dependencies.
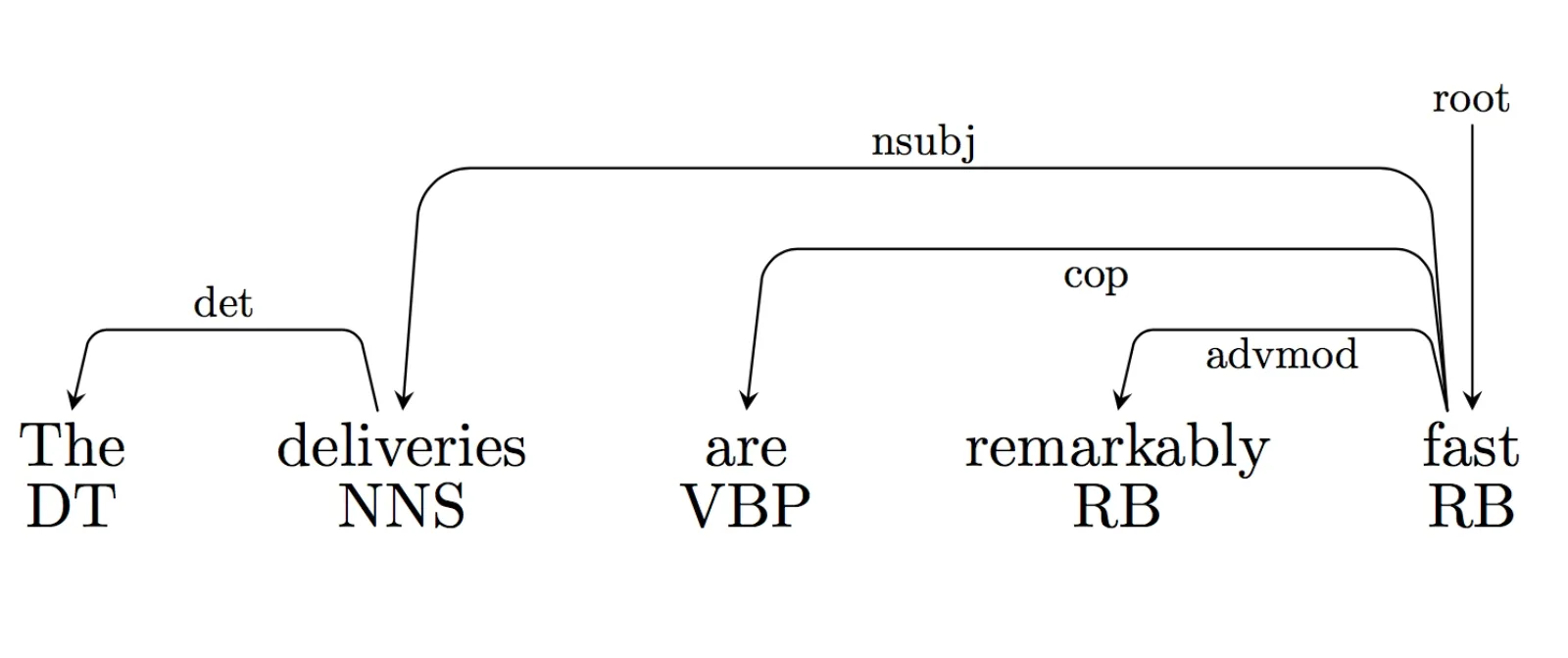 A dependency parse tree. The word "remarkably" has an incoming advmod link, which has the definition: "An adverbial modifier of a word is a (non-clausal) adverb (RB) or adverbial phrase (ADVP) that serves to modify the meaning of the word."
A dependency parse tree. The word "remarkably" has an incoming advmod link, which has the definition: "An adverbial modifier of a word is a (non-clausal) adverb (RB) or adverbial phrase (ADVP) that serves to modify the meaning of the word."Dependency parse trees are internally a prediction process using a trained model, and even though the accuracy is high, there is a chance we get incorrect parse trees, depending on the sentence. We’ll create a few features based on this tree. Each word will have the following features:
Part of Speech (POS)-tag of the word
The previous two and the following two words' POS-tags
A boolean indicator (0 or 1) for every outgoing link type, e.g.
out_advmod = 1A boolean indicator (0 or 1) for every incoming link type, e.g.
in_nsubj = 1
Deliveries will have a feature vector as follows:
Feature | Value | Explanation |
|---|---|---|
pos | NNS | the part of speech tag |
pos_prev2 | - | |
pos_prev1 | DT | POS tag of 'the' |
pos_next1 | VBP | POS tag of 'are |
pos_next2 | RB | POS tag of remarkably |
out_det | 1 | There is an out-link of type 'det' |
in_nsubj | 1 | There is an in-link of type 'nsubj' |
in_advmod | 0 | There is no in-link for 'advmod', noted as 0 |
in_nmod | 0 | ... |
... | 0 | zeros for all non-present in/out links |
3. Model training
In order to feed our feature vectors as input to our neural network, we’ll need to transform our current feature vector into float values. Note that our current feature vector includes values of type string. How do you convert a string to a float? You don’t.
We’ll use one of the standard approaches for this: One hot encoding. For every possible POS-tag, we’ll create a new binary feature. We’ll then mark the current feature’s value by putting a 1 in the sub-feature that represents that tag. Like so:
Word | pos_DT | pos_NNS | pos_VBP | pos_RB |
|---|---|---|---|---|
The | 1 | 0 | 0 | 0 |
deliveries | 0 | 1 | 0 | 0 |
are | 0 | 0 | 1 | 0 |
remarkably | 0 | 0 | 0 | 1 |
fast | 0 | 0 | 0 | 1 |
Why is it called one hot encoding? Because one of the features is hot, and marked as a one. You can think of this step as putting a word into a category bin, where the bin’s name is the word itself, and not putting it in any other bins.
This methodology is often used when you’re working with actual words as features, but brings up the dimensionally of your feature to multiple thousand dimensions (this is usually fine, since the matrices are sparse). In our case, we don’t include the actual word as a feature, but we still have to do this, since the POS-tags are strings.
The observant reader might have noticed that we’ve already done a slightly similar but different version of this step for the in and out-links features. Since we defined our features as binary, and named them 'in_nsubj' etc, we’ve essentially created a similar encoding for our link features. We’d put 1’s in all bins where there is an in- or out link, respectively. The only difference here is that a word might have multiple in links, and multiple out links, hence the separation.
Given our 27 training sentences, we have a total of 253 used features (after encoding), resulting in an input layer of size 253. We'll use a few hidden layers of different sizes, and an output layer of size 5, one for each category.
Training the model is as simple as feeding the feature vectors and correct labels for all our training examples into the neural network model that we’ve defined. We can then cross validate (or use a separate test set) to measure the performance of our model (my example code with 27 sentences of training has an accuracy of about 81%).
You can try the model here: OskarHandmark/nlp-deep-learning
Since we’ve trained this model with a categorical output (our final layer has 5 outputs), we can get the probabilities assigned to each output for a given word during prediction:
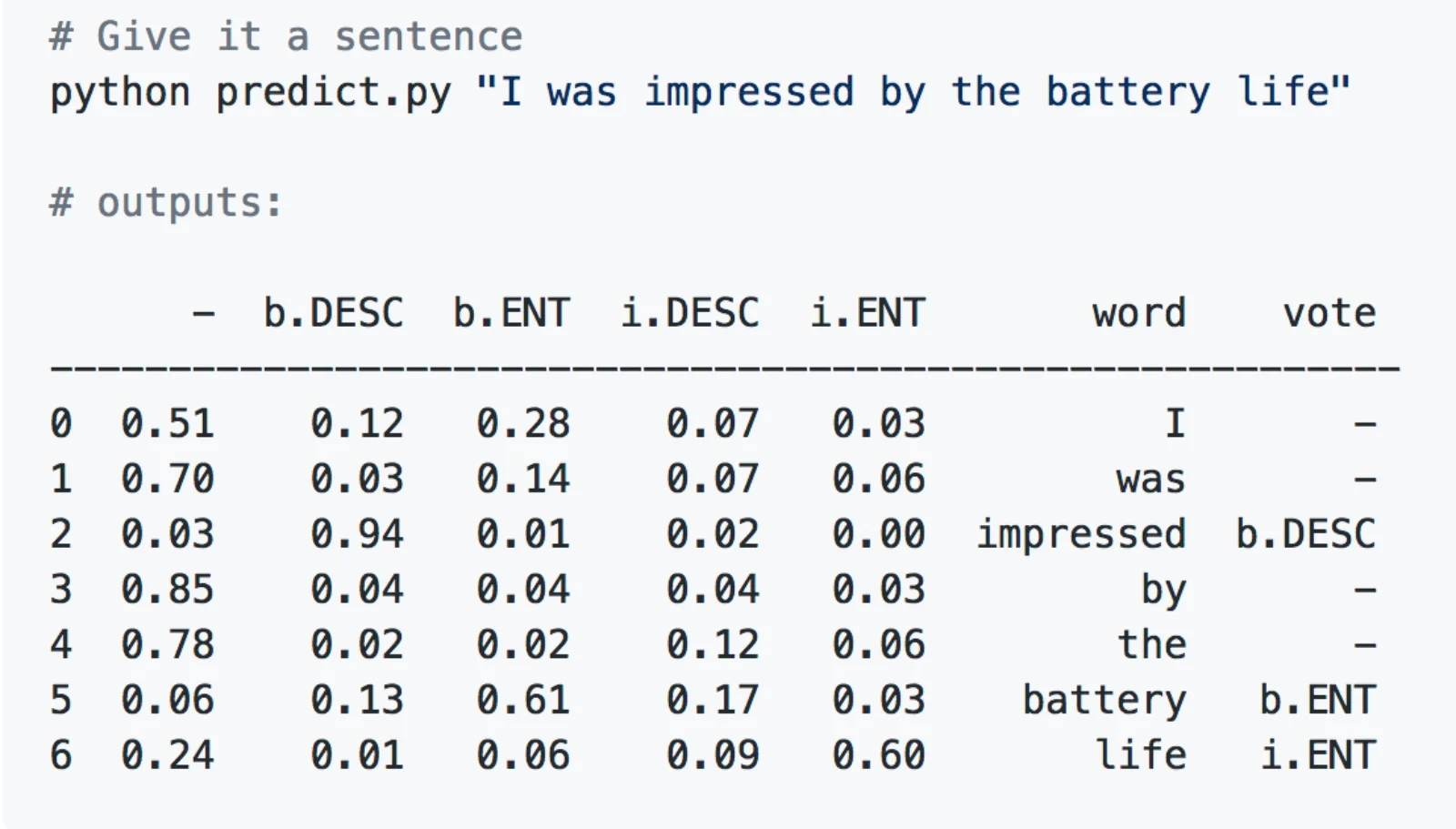
4. Linking
This is a post-prediction step in which we link the entities and descriptors together. After the model has made its predictions, we’ll look at the dependency parse tree again, and follow the following simple heuristic:
If there is a link between any of the words in the entity group, to any of the words in the descriptor group, we’ll say they are connected. If there are more descriptors than entities, we allow multiple descriptors to be linked to the same entity, and vice versa.
We’ll also look for negations and transform words to their lemma-forms (i.e impressed → impressive). For example, imagine a sentence like:
“I was impressed by the battery life, but not by the design.”
And our classifier produced a correct classification of:
Word | Predicted class |
|---|---|
I | - |
was | - |
impressed | b.DESC |
by | - |
the | - |
battery | b.ENT |
life | i.ENT |
, | - |
but | - |
not | - |
by | - |
the | - |
design | b.DESC |
. | - |
Follow all original dependency parse tree links (for the predicted groups):

impressed → [nmod] → life design → [conj] → impressed design → [neg] → not
To produce the results:
Battery life: impressive Design: Not impressive
When everything’s in place. Running this for a lot of sentences and then aggregating the results is where things become useful. Sentiment analysis could be performed on the descriptors with ease. Imagine you had a few hundred or thousand reviews of one of your products (looking at you Amazon...), you'll have a summary of the pros and cons of that product, like the introductory image suggested:
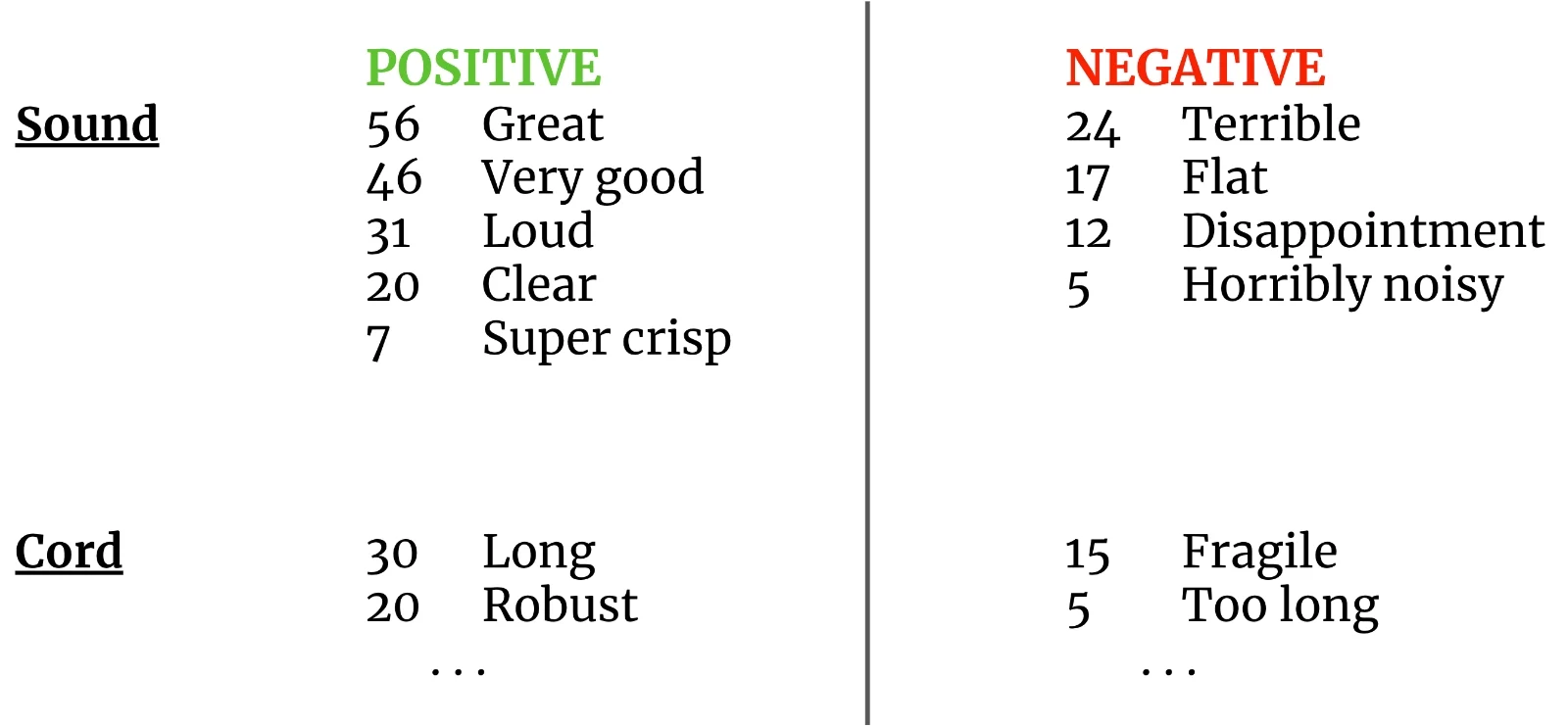 Aggregated result for hypothetical headphone reviews.
Aggregated result for hypothetical headphone reviews.Published on December 4th 2018
Last updated on March 1st 2023, 10:56

Oskar Handmark
Founder & Venture lead